Building an AI Micro-SaaS in 9 Days: A Field Report
An honest field report on AI programming in September 2025
The Bottom Line
I built a complete AI micro-SaaS platform in 9 days that solves a real business problem and generates revenue (SceneMind.ai). If you're considering a similar project, here's what it actually took:
- 69 commits on the AI pipeline (Python/Prefect)
- 150 messages and 120 edits in Lovable for the full-stack platform
- $18 spent on Lovable
- The cost of an AI coding assistant (OpenAI Codex, Claude Code etc.)
This is 4.5 months after Karpathy's vibe coding experience. His app was much simpler: no database, processing done on the spot, straightforward AI work (extract menu items and turn them into images). Yet developing it required several days of work and significant pain, even for the legendary computer scientist who actually coined the term "vibe coding."
Karpathy's experience was a mix of exhilaration and pain. The exhilaration came from seeing his idea quickly come alive in Cursor. The pain came from deployment and what he called the "IKEA problem": assembling all the services, docs, API keys, configurations, dev/prod deployments, rate limits, and pricing tiers. As he put it, "I spent most of it in the browser, moving between tabs and settings and configuring and gluing a monster."
I wanted to revisit this problem 4.5 months later with more ambitious goals: a full micro-SaaS with frontend, backend, and complex AI pipeline. The tools have evolved since Karpathy worked with Cursor - we now have Codex, Claude Code, Lovable, and others. This is a field report of what it actually feels like to build with AI today, what works well, and what still causes pain.
The platform I built processes movie scripts for VFX producers, converting unstructured PDFs into organized spreadsheets. This was very difficult to automate before LLMs, but now runs autonomously in around 10 minutes per script.
We've moved beyond just using AI to write code. I'm now using AI to operate the entire system, from development to monitoring.
First, Some Fun Numbers
I started the sprint on September 12th and closed it on September 21st.

I ran the numbers on the GitHub commits, which we can see as a rough proxy of work volume.
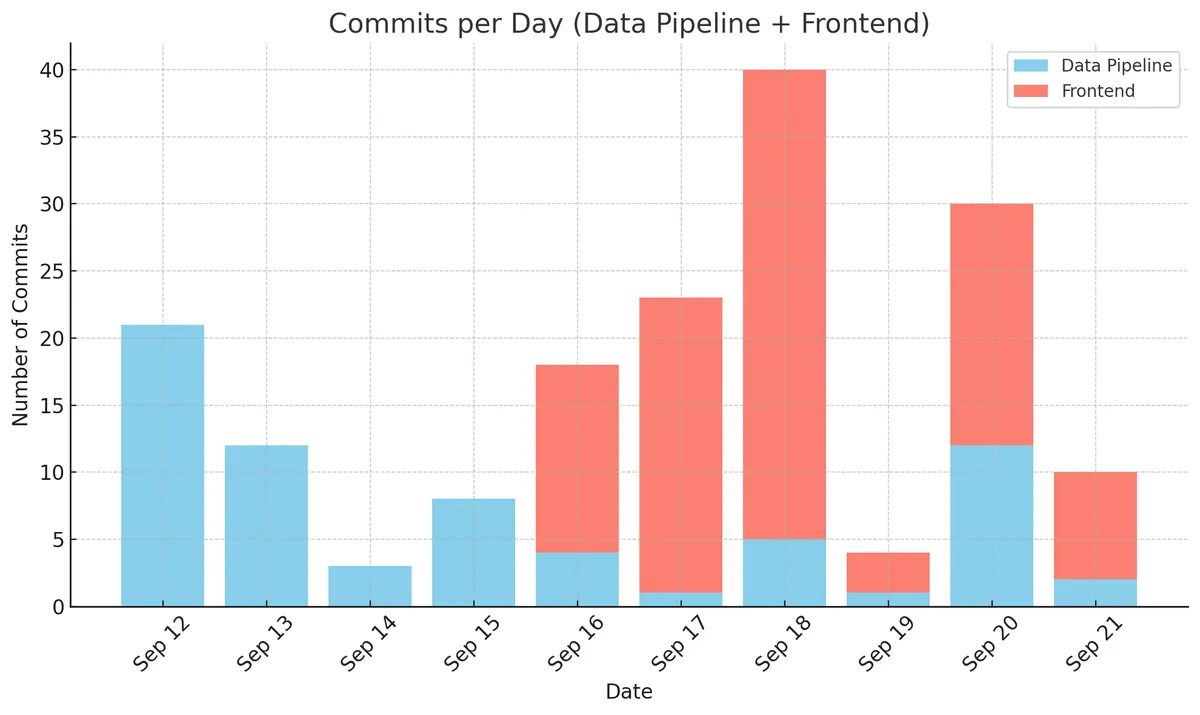
The blue commits (69 in total) relate to the Python AI pipeline for the script breakdown, which I built locally with my coding assistants. The red commits (100 total) are made by Lovable, which I used to build the actual platform (frontend and backend).
Looking at the blue bars, you can see the initial enthusiasm on the first day (September 12th) when I must have coded 12 hours in a row. This was the "honeymoon" phase which all vibe coders know well. Everything goes splendidly, your ideas materialize in an instant, and you're convinced that everything will be done in two days.
Then reality sets in as all the bugs, edge cases and complications appear. Still carried by the initial momentum, you push through, albeit with a bit less energy (September 13th). Then exhaustion sets in (September 14th).
Then you either give up... Or you sober up from the honeymoon, accept that programming is still hard (even with AI) and settle into a sustainable pace!
The Problem I Solved
VFX producers work on the special effects for films and TV shows. When they receive a movie script that's going into production, they need to break it down to identify what special effects the show needs, estimate costs, and submit budgets to producers. The challenge is that many scripts arrive as raw PDFs with no structure whatsoever.
Currently, VFX producers have to manually break down these scripts, often literally copy-pasting each scene and dialogue segment from the PDF into a spreadsheet. For a feature film script, this can take several hours of tedious work before they can even begin the actual analysis.
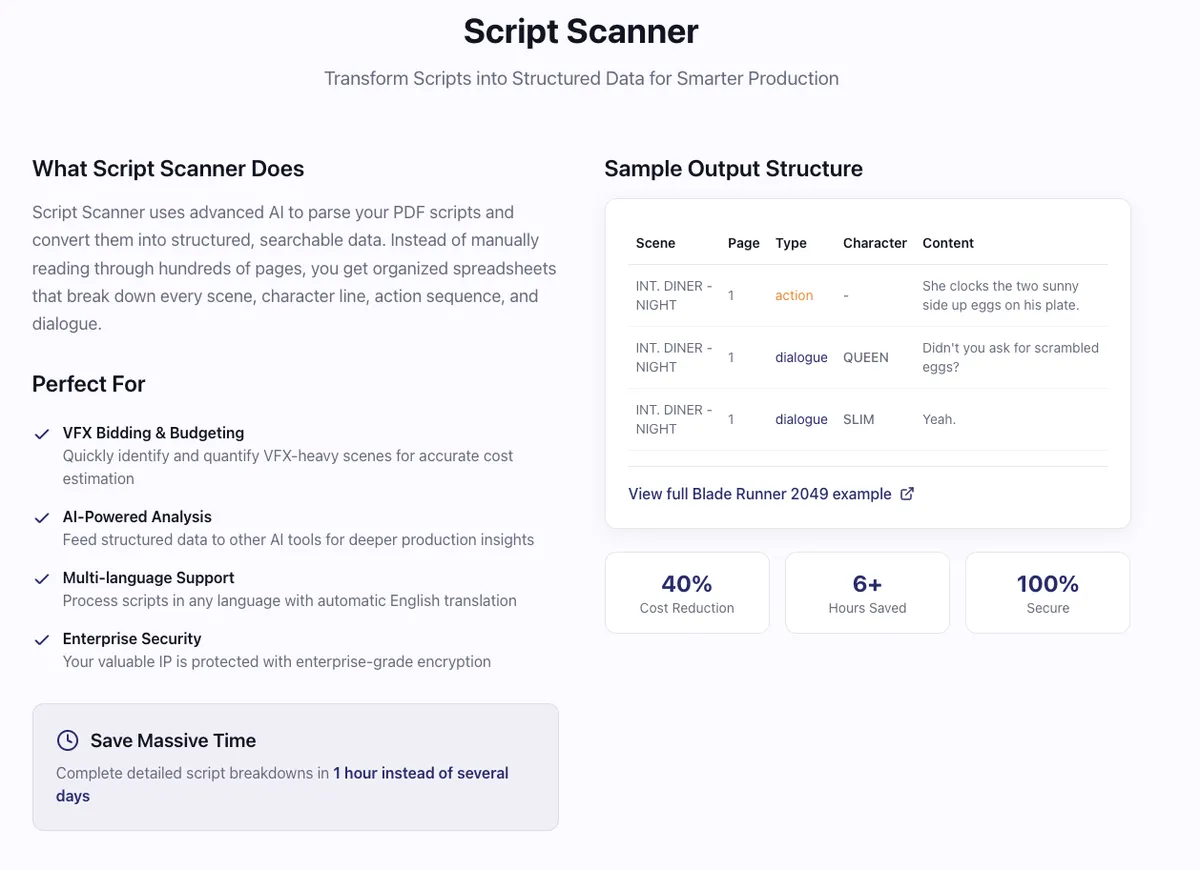
This is where Script Scanner comes in. It's an AI pipeline that automatically converts these unstructured script PDFs into organized tables like this one, ready for import into whatever analysis tools the producer prefers.
The technical challenge here is more nuanced than it might initially appear. Scripts need accurate scene identification and simultaneous segmentation and classification. Consider this snippet from a typical script:

We need to identify the scene header, separate the three action elements, and distinguish the dialogue - all while maintaining perfect accuracy. You might think regex could handle this, but scripts vary enormously despite formatting standards. At the same time, you can't just send the entire PDF to an LLM and hope for the best, because there's zero margin for error. Producers need a perfectly accurate breakdown, which means the pipeline requires extensive quality controls and validation layers.
This type of problem - too complex for traditional automation, too important for LLM hallucinations - represents a sweet spot for modern AI tooling when properly implemented.
Architecture: Building for AI-First Operations
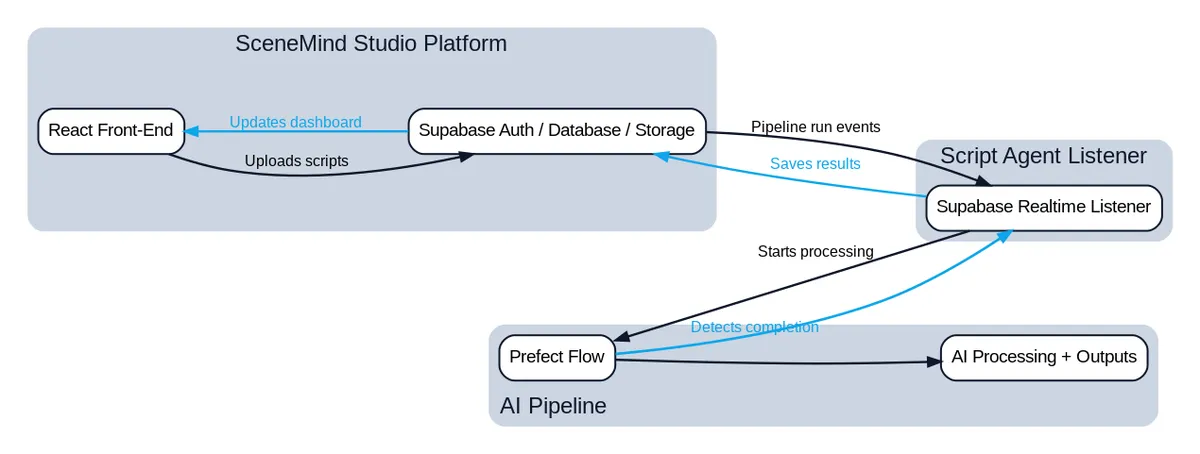
Frontend and Backend: Built with Lovable using React and Supabase. This handles user authentication, file uploads, credit management, and result delivery.
AI Pipeline: A Python service using Prefect for orchestration, combining traditional data processing with LLM API calls across 22 discrete tasks.
Connector Service: A listener that manages the flow between the platform and pipeline. It detects when users start jobs, triggers the appropriate workflows, monitors completion, and handles both success and failure scenarios.
External Integration: Google Sheets integration for delivering results in a format VFX producers can immediately use.
The user experience is straightforward: sign up, upload scripts, spend credits to trigger processing, and receive structured results. If processing fails for any reason, credits are automatically refunded.
When pipelines fail (and they will), I fix them alongside an AI operator agent that has full access to logs, metrics, and recovery procedures.
How the Tools Have Evolved
Karpathy's experience highlighted what he called the "IKEA problem" - the reality that building modern applications involves assembling a complex array of services, each with their own documentation, API keys, configuration requirements, and integration quirks. Even with AI helping to write code, developers still spent most of their time in browser tabs, configuring services and debugging connections.
Four and a half months later, here's what's changed:
Better AI Coding Tools: We now have options beyond Cursor, including Claude Code, OpenAI Codex, and specialized coding agents. More importantly, these tools have gotten significantly better at understanding context and maintaining consistency across complex codebases.
Integrated Development Platforms: This is where the real progress has happened. Platforms like Lovable implement full-stack development patterns and automatically handle many of the integration challenges that previously required manual configuration.
AI-Driven Operations: The pipeline operator agent I use reads comprehensive operational manuals, diagnoses failures, and suggests specific fixes.
Service Integration Intelligence: Modern platforms are increasingly opinionated about which services to integrate and often handle the connections automatically. For example, Lovable will integrate SendGrid into your app if you need to send emails, and you will simply need to provide a SendGrid API key when the agent asks for it.
That said, some pain points persist. Google integrations still require navigating complex OAuth flows, managing service accounts, and clicking through confusing UI flows.
The "IKEA problem" isn't solved, but platforms like Lovable are making significant progress by providing pre-integrated, opinionated solutions that reduce the number of pieces you need to assemble manually.
Technical Implementation Deep Dive
Building the AI Pipeline
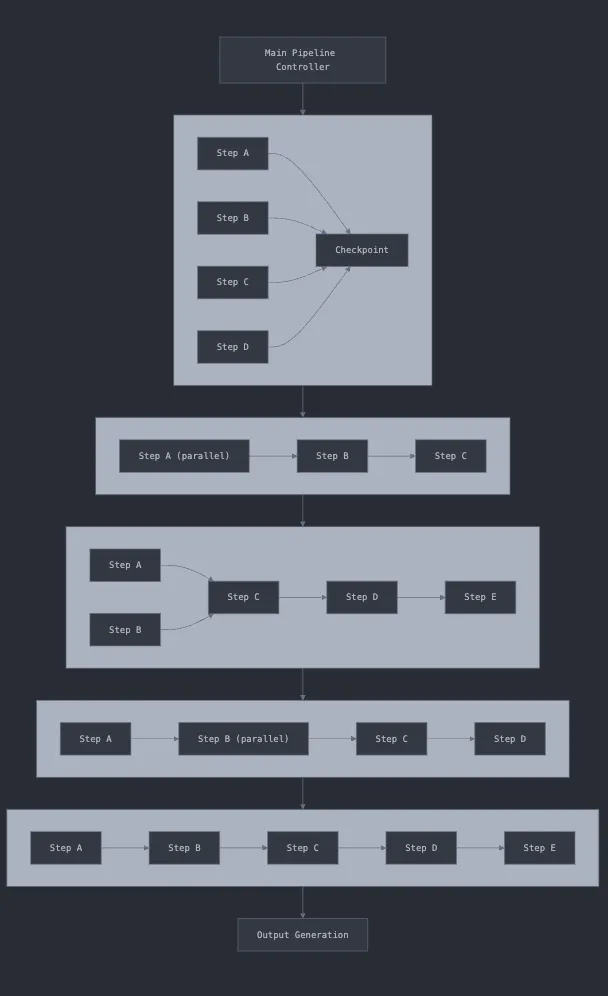
The pipeline steps are censored to maintain business confidentiality.
The processing pipeline represents the heart of the system - 22 tasks organized into 5 logical subflows that combine Python logic with LLM API calls:
PDF Processing: Extract and transcribe pages in parallel.
Metadata Extraction: Identify script title, authors, and boundaries between title pages and actual script content. This step uses GPT-5-mini with structured outputs to ensure consistent data formats.
Scene Segmentation: Break the script into individual scenes using dual approaches - both regex-based pattern matching and LLM classification. We measure agreement between these approaches as a quality signal.
Content Classification: Separate action lines, dialogue, and scene headers within each scene. This is where the complexity really shows up, because scripts can have inconsistent formatting even within the same document.
Quality Assurance: Multiple validation layers including string distance measurements, cross-method agreement checks, and global sanity tests using more sophisticated LLMs.
Key Architecture Decisions That Mattered:
Choosing Prefect for Orchestration: This decision came down to AI compatibility. I needed an orchestrator that coding agents could operate effectively through command-line interfaces. Prefect handles retries, timeouts, and parallelism automatically, which is crucial when you're making dozens of LLM API calls that can fail for various reasons.
Separating Prompts from Code: All prompts live in versioned Markdown files rather than being embedded in Python strings. This makes it much easier to iterate on prompts with AI assistance and track what changes actually improve performance.
Extensive Quality Controls: Six of the 22 tasks exist purely for validation. We compare different text extraction approaches, measure string distances, and run global sanity checks with the most capable models.
Comprehensive Monitoring: Every LLM call gets logged with token counts, costs, and request IDs. When you're debugging non-deterministic systems, this observability becomes essential.

A JSONL entry logging an OpenAI API call. The LLM logging system was built from scratch.
Platform Development with Lovable
I originally planned to use Lovable just to draft a basic frontend, then export the code for local development with traditional tools. Instead, I ended up building the entire platform there, including complex backend logic. This was the biggest surprise of the project.
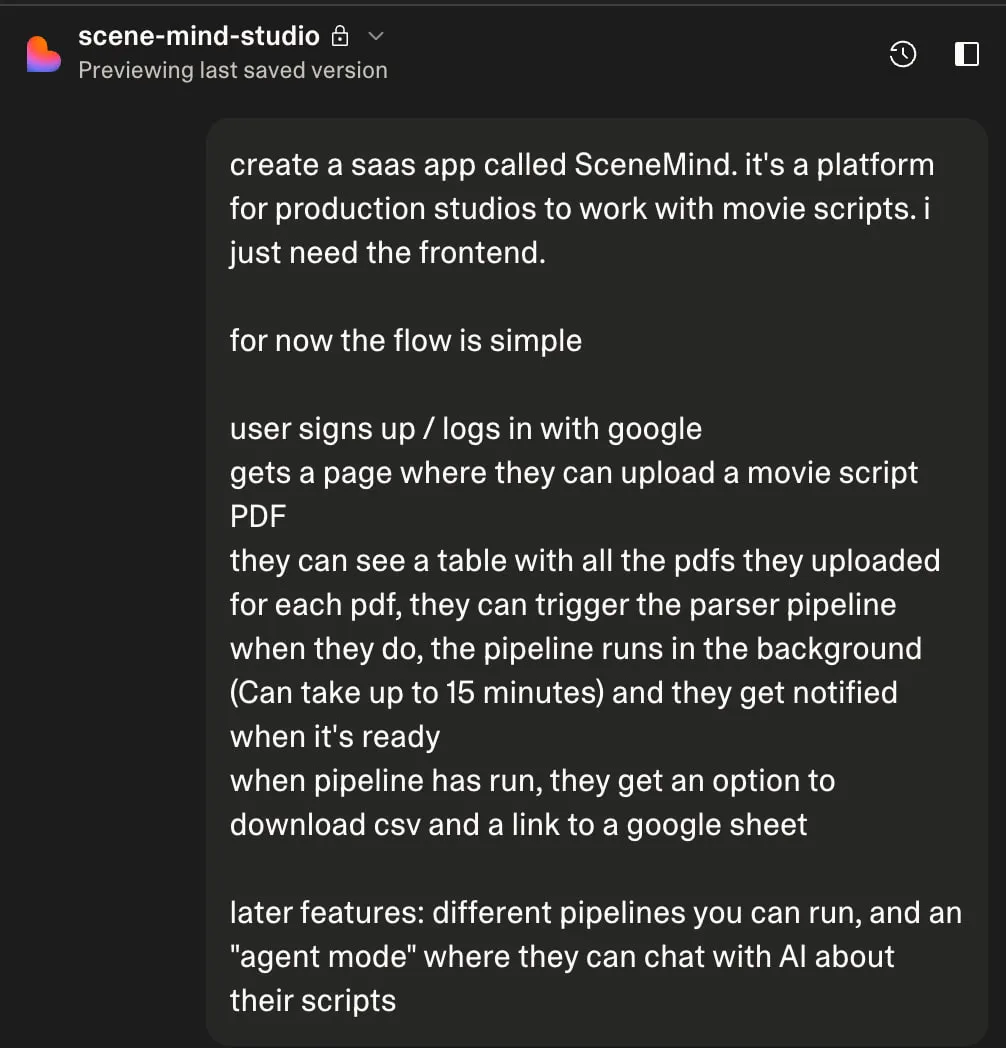
What Worked Better Than Expected:
The conversation interface uses a single thread that makes development feel natural, but behind the scenes Lovable manages context intelligently. You can click on UI elements and write targeted prompts, which helps the AI understand exactly what you're trying to modify.
The Supabase integration works quite well. Lovable automatically created properly normalized database tables, implemented role-based access controls, set up real-time subscriptions, and built edge functions for complex business logic.
What Lovable Handled Automatically:
- Google OAuth setup (though this still required manual Google Cloud configuration)
- Edge functions for user management, credit tracking, and PDF processing
- Real-time database subscriptions for job status updates
- Object storage for file uploads and results
- Security reviews and performance analytics
- Git integration with automatic commits and deployment
Deployment and Domain Setup:
When I was ready to go live, I already had a domain I'd bought on Namecheap previously. Lovable provides a working staging domain while you develop, but for production I needed to connect my custom domain. Lovable attempted to automate the DNS configuration by providing a direct link to update Namecheap records, which would have been amazing if it worked. Unfortunately, there was an unnamed error, so I had to manually update the DNS records myself (it took 10 minutes).
Once the domain was connected, deploying was seamless. Lovable handles the entire deployment pipeline, so going from development to production was just a matter of hitting the publish button.
Product Work and Iteration:
The most rewarding part was the product work - figuring out how the platform should actually function for users. The initial layout worked but was confusing, with information poorly organized. I did extensive iterations with the Lovable agent, often using Wispr Flow to voice-describe what wasn't working and how we could rearrange elements. The tight feedback loop let me try a dozen different prototypes quickly until I found something clean and organized.
This made me realize that when you can rapidly prototype interfaces, the final result depends heavily on your taste, product sense, and user understanding. AI is excellent at implementing what you ask for, but it's not trained to imagine great interfaces from scratch; that's still a human skill.
Built-in Platform Features:
Lovable provides several features that would normally require separate services. The analytics dashboard gives you site traffic and user behavior insights out of the box. There's an automated security review that flags potential vulnerabilities in both frontend and backend code: when you click on the "fix issue" button, a targeted prompt is sent to the agent which then tries to solve it.
There's also performance analytics. In settings, you get your web app rated on performance, accessibility, best practices, and SEO. Each section provides specific to-dos, and again you can ask the agent to fix these directly.
All in all, 75.3 of my 200 monthly Lovable credits (roughly $18) built a complete full-stack application that would have taken weeks with traditional development approaches. The cost efficiency combined with the integrated tooling made it feel like working in the future of web development.
Development Workflow and Tools
The tool selection process deserves discussion because it significantly impacts productivity:
Primary Coding Agent: I used OpenAI Codex in VS Code, switching to GPT-5-Codex when it became available mid-project. Codex excels at finding complex bugs and providing thorough code reviews, but it's slower than alternatives because it thinks deeply about problems. There were moments of intense frustration when it would overthink simple issues, but every major breakthrough came from Codex's persistent investigation.
Quick Fixes: Warp Terminal and Amp (both using Claude Sonnet 4) proved excellent for simple issues where I didn't want Codex overthinking.
Voice Interface: Wispr Flow dramatically improved my prompting quality. When you speak instead of type, you naturally provide more context and detail, leading to better AI understanding. This was especially valuable for complex architectural discussions.
Wispr Flow is a great tool.
High-Level Planning: ChatGPT-5 Pro and Thinking models handled research, documentation review, and strategic planning that required web access or complex reasoning.
Documentation Strategy:
I created a docs/ folder structure that became crucial for AI collaboration:
- Implementation plans (usually AI-generated after discussion)
- Mermaid diagrams for visual architecture planning
- Operational manuals for pipeline management
- Context files for specific system components
- Automated CI workflows that generate complete codebase snapshots
This documentation serves as extended memory for AI agents, allowing them to maintain context across long development sessions.
Visual Planning with Mermaid:
One discovery worth highlighting: getting AI to create Mermaid diagrams before coding led to better architectures. I'd describe the workflow conceptually, have Codex generate a .mmd file, iterate on the visual representation until it looked right, then implement the actual code. This visual-first approach caught architectural issues early.
The pipeline operator agent
One of the most valuable parts of this project was creating an AI agent specifically to operate and troubleshoot the pipeline.
Data pipelines fail constantly. When you're making dozens of LLM API calls, processing PDFs, and integrating with external services, something will break. Traditionally, this means manually digging through logs and debugging issues that can take hours to understand.
I created a comprehensive operational manual in Markdown that explains how the pipeline runs, common failure modes, and recovery procedures. This becomes the agent's knowledge base. When issues arise, I work with the operator agent in a chat session where it has full command-line access to the Prefect deployment, can query logs, check status, and restart failed tasks. The agent also has access to the Supabase database through an MCP connector, so it can check job statuses, user data, and troubleshoot issues that span both the pipeline and the web platform.
The key requirements are comprehensive documentation that covers failure scenarios, command-line access for the agent, and iterative learning where we update the manual after each incident.
This approach fundamentally changes the economics of running complex systems since you can delegate operational work to AI agents trained on your specific system's behavior.
For anyone building AI-powered applications, I'd recommend designing systems from the start to be AI-operable. Choose tools with good CLI interfaces, maintain comprehensive operational documentation, and think about how an AI agent would debug issues in your system.
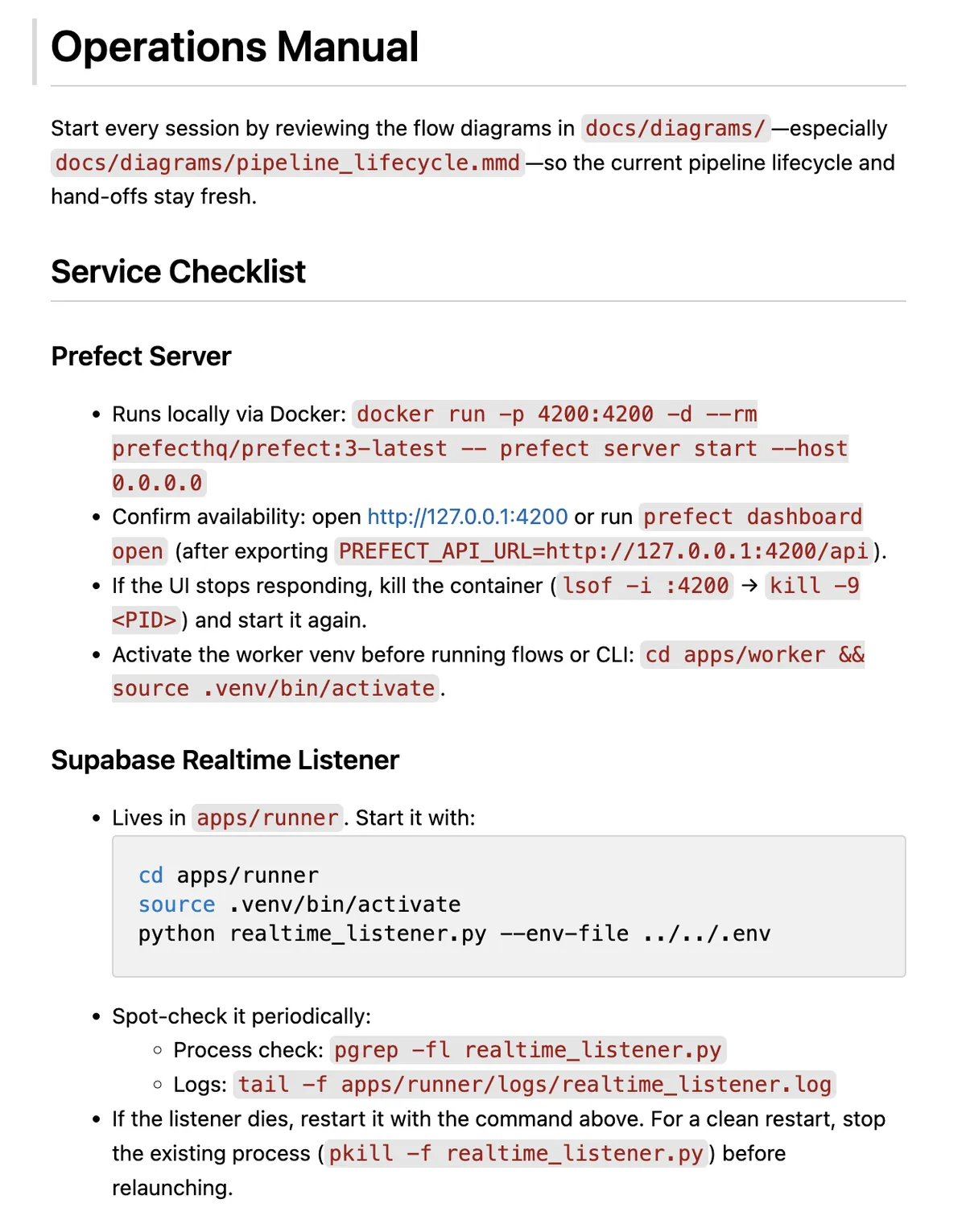
The first part of the operational manual for the pipeline manager agent.
Staying connected with NTFY
As the sole admin, I need immediate alerts for platform events - new users, pipeline failures, successful completions. I found a simple solution using NTFY, a free notification service. You choose a channel name and any service can send notifications with a simple POST request. The NTFY app on my phone receives these instantly, keeping me connected to the platform's health without constantly checking dashboards.
For security, I generated a complex channel name that works like a password since NTFY has no authentication. I also ensure notifications never contain sensitive data - they're informative enough to be useful but safe even if intercepted. When a user starts processing or a pipeline fails, I know immediately rather than discovering issues hours later.
Key Insights: What Actually Works
What Works Well
Lovable's Integration Ecosystem: The platform goes beyond code generation to provide an opinionated development experience. When I mentioned needing email functionality, it suggested SendGrid and provided the integration form. When I needed analytics, it automatically configured tracking. This reduces cognitive load significantly: instead of researching and comparing options, I could focus on business logic.
AI Operations: The pipeline operator agent with comprehensive operational manuals saves hours on debugging and monitoring. Today, AI can effectively operate complex systems when given proper documentation and command-line access. This shifts the bottleneck from technical implementation to documentation quality.
Voice-Driven Development: Using Wispr Flow for voice-to-text dramatically improved prompt quality. Spoken prompts are naturally longer and more contextual than typed ones, leading to better AI understanding and fewer iteration cycles.
Visual Architecture Planning: Creating Mermaid diagrams with AI before coding resulted in cleaner implementations. The visual representation helped identify missing components and architectural inconsistencies that would have caused problems later.
Persistent Pain Points
Google Integration Complexity: Despite all the advances in AI tooling, Google services remain frustratingly complex to integrate. The OAuth setup required navigating multiple UIs, managing service accounts, configuring consent screens, and understanding complex permission models. AI agents cannot handle workflows that require clicking through graphical interfaces.
Payment Processing Challenges: Modern payment infrastructure isn't as plug-and-play as it should be. Lemon Squeezy rejected my application after manual review without explanation, forcing me to fall back to manual invoicing. While Stripe integration is available through Lovable, it requires handling VAT and tax compliance yourself.
Deployment Complexity: Moving from development to production remains non-trivial. My pipeline currently runs on a home server, and migrating to managed cloud infrastructure with proper Prefect deployment represents a significant remaining task.
Business Operations: Everything beyond technical implementation - compliance, marketing, customer support, financial management - still requires substantial human intervention. The technical barriers have lowered dramatically, but business operations remain largely unautomated.
Current State and What's Next
What's Live and Working:
The SceneMind.ai platform is fully operational with user authentication, a credit-based pricing system, autonomous script processing, and Google Sheets integration for result delivery. The NTFY notification system keeps me informed of system events and user activity.
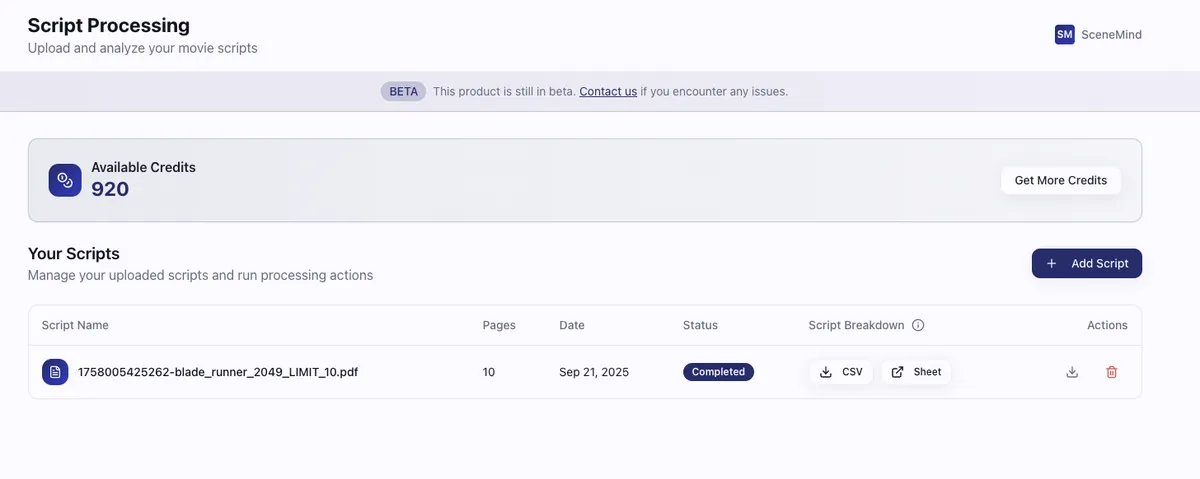
Major Remaining Tasks:
Cloud deployment with managed Prefect infrastructure represents the biggest technical TODO. Currently running on a home server limits scalability and reliability.
Payment processing needs a proper solution, probably through Stripe integration via Lovable, though this means handling tax compliance manually.
Building evaluation datasets for the AI pipeline would enable systematic optimization of model choice, prompt effectiveness, and cost efficiency.
Revenue Model and Scaling:
I needed a pricing system that could handle uncertainty. Since I'm building a platform for multiple AI services (not just script breakdown), and I can't predict what future workflows will cost or where LLM pricing will go, I went with a simple credit system.
When I create a new workflow, I measure my actual cloud costs - let's say processing a script costs me 10 euros. I convert that to credits and add a markup for my time and platform overhead. With a 25% markup, that workflow now costs users 12.5 credits. Everything on the platform runs on credits.
I give every new user 1,000 free credits so they can try the service without commitment. Then I created three pricing tiers - if you subscribe monthly, you get cheaper credits with a bulk allowance. If you need more, you can top up at subscriber rates. If you don't want to subscribe, you can buy credits directly, but they cost a bit more.
This approach provides flexibility. As I add new AI workflows for VFX producers, I just price each one based on its actual costs plus my markup. The credit system scales naturally without me having to restructure pricing every time.
If you're building something similar, I'd recommend tying your pricing directly to variable costs with a clear markup. It keeps your unit economics predictable even when you're not sure what you'll build next.
Practical Advice for Similar Projects
Before You Start
Understand Your Problem Deeply: The most important step happens before you write any code. Spend time with potential users understanding their current workflow, pain points, and what "good enough" looks like. My VFX producer friend's detailed explanations of current manual processes were essential for designing the right solution.
Validate Economic Viability: Make sure AI can solve your problem cost-effectively. Run small tests with LLM APIs to estimate per-unit costs, then work backwards to pricing that makes sense for your target market.
Start Narrow: Resist the temptation to build a feature-rich platform. I focused exclusively on script breakdown, not the dozen other AI tools I could imagine VFX producers wanting. Get one workflow working perfectly before expanding.
Plan with AI: Use capable models like ChatGPT-5 Pro or Claude for initial architecture planning. They're excellent at identifying potential issues and suggesting implementation approaches you might not have considered.
Development Workflow Recommendations
Create a Documentation System: Set up a docs/ folder from day one with plans, architectural diagrams, and context files. AI agents work much better when they have comprehensive project context to reference.
Use Visual Planning: Generate Mermaid diagrams for complex workflows before coding. The visual representation helps both you and AI understand the system architecture more clearly.
Leverage Voice Input: Whether through Wispr Flow or another solution, voice-to-text dramatically improves prompt quality. Spoken explanations naturally include more context and nuance.
Match Tools to Complexity: Use sophisticated agents like Codex for complex debugging and architecture work, but switch to faster tools for simple changes. Don't overthink simple problems.
Version Everything: Use atomic Git commits with AI-generated messages. For important features, create branches and open PRs with AI-generated reviews. This creates a searchable history of your development process.
For LLM-Powered Applications
Choose Your Orchestrator Carefully: Look for tools that AI agents can operate through command-line interfaces. Prefect worked well because Codex could manage it entirely through CLI commands.
Separate Prompts from Code: Store all prompts in versioned Markdown files. This makes iteration much easier and enables better collaboration with AI on prompt optimization.
Build Extensive Quality Controls: For applications where accuracy matters, implement multiple validation approaches and measure agreement between them. Six of my 22 pipeline tasks exist purely for quality assurance.
Monitor Everything: Log every LLM call with tokens, costs, and request IDs. When debugging non-deterministic systems, comprehensive observability becomes essential.
Create Operational Documentation: Write detailed manuals for AI agents to use when operating your systems. This enables AI-assisted debugging and monitoring, which scales much better than manual operations.
Reality Check and Expectations
The Honeymoon Phase: The first day or two will feel magical as your prototype rapidly takes shape. This initial excitement is real, but it represents maybe 20% of the actual work required.
The Complexity Curve: Once you move beyond basic functionality, you'll encounter edge cases, integration challenges, and operational complexity. This is normal and expected.
Testing Is Still Essential: You need to test every user path, understand your data flow end-to-end, and plan for all the ways things can fail. AI makes building faster, but it doesn't eliminate the need for thorough testing.
Business Skills Matter More: With technical barriers lowering, product sense, user understanding, and business operations become the primary differentiators. AI can help you build anything; the challenge is building the right thing.
Looking Forward: The Bigger Picture
The technical challenges of building software are rapidly becoming solved problems. What remains is everything else that makes a business successful: understanding customer needs, creating delightful user experiences, handling operations, managing growth, and building sustainable revenue models.
This creates an interesting opportunity. I hope AI platforms like Lovable will continue evolving toward full business automation: imagine coordinating everything from application development to entity creation to marketing campaigns in a single AI-powered environment!
The limiting factors are shifting from "can I build this?" to "should I build this?" and "how do I operate this successfully?" These are fundamentally human challenges that require creativity, empathy, and business judgment.
For developers considering similar projects: the tools are ready. The main question is whether you're ready to think beyond the code and embrace the full scope of what building a business requires.
This field report represents my experience in September 2025. The tools and landscape continue evolving rapidly, but the trajectory is clear: building software is becoming dramatically easier, and success increasingly depends on everything else that surrounds the code.